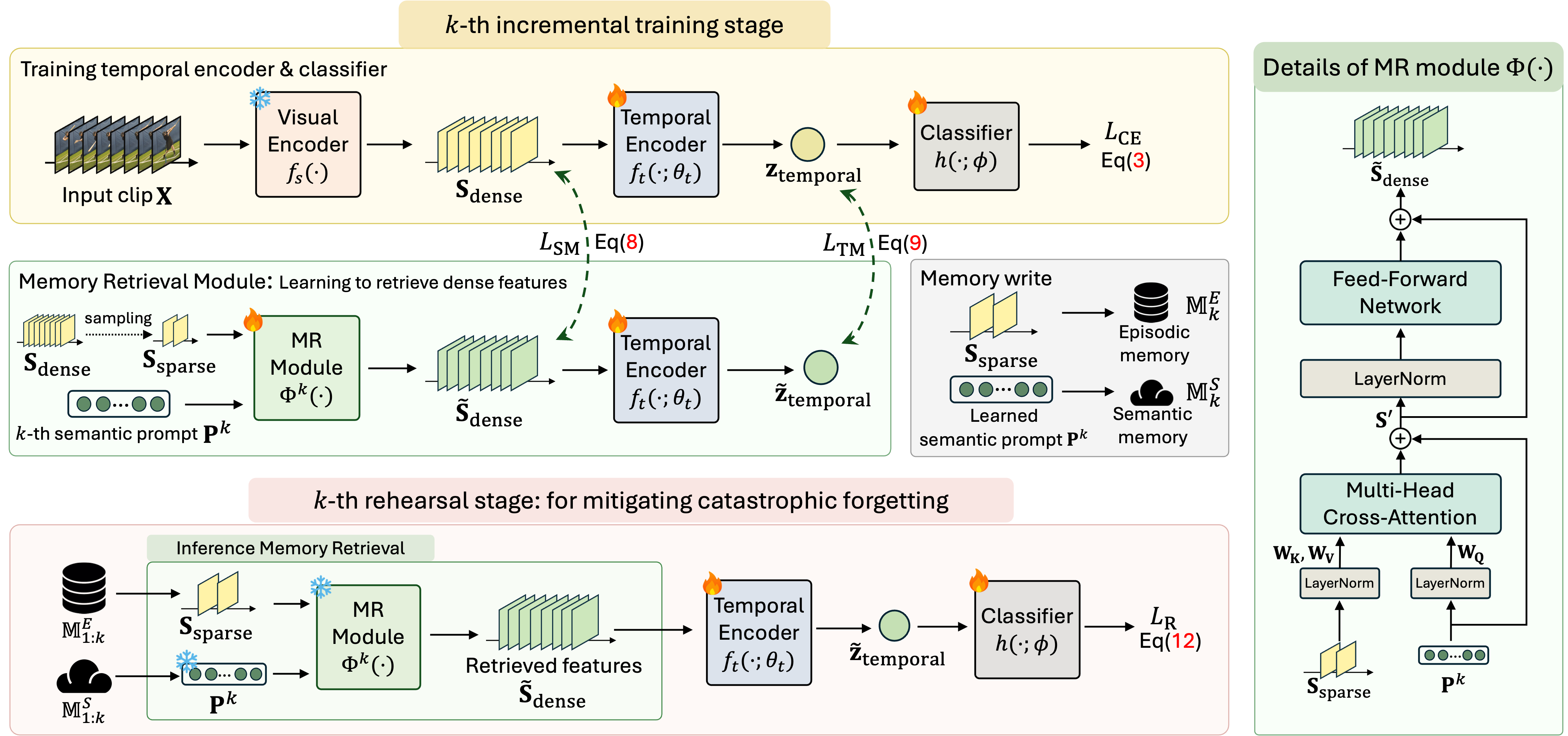
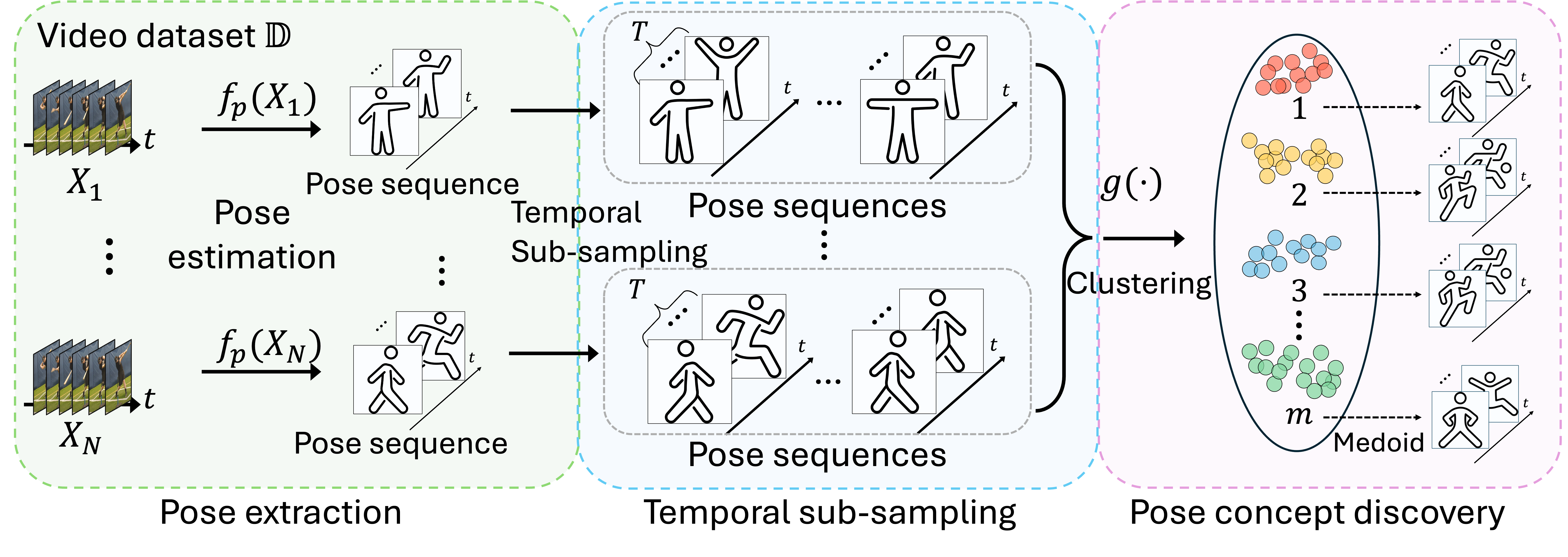
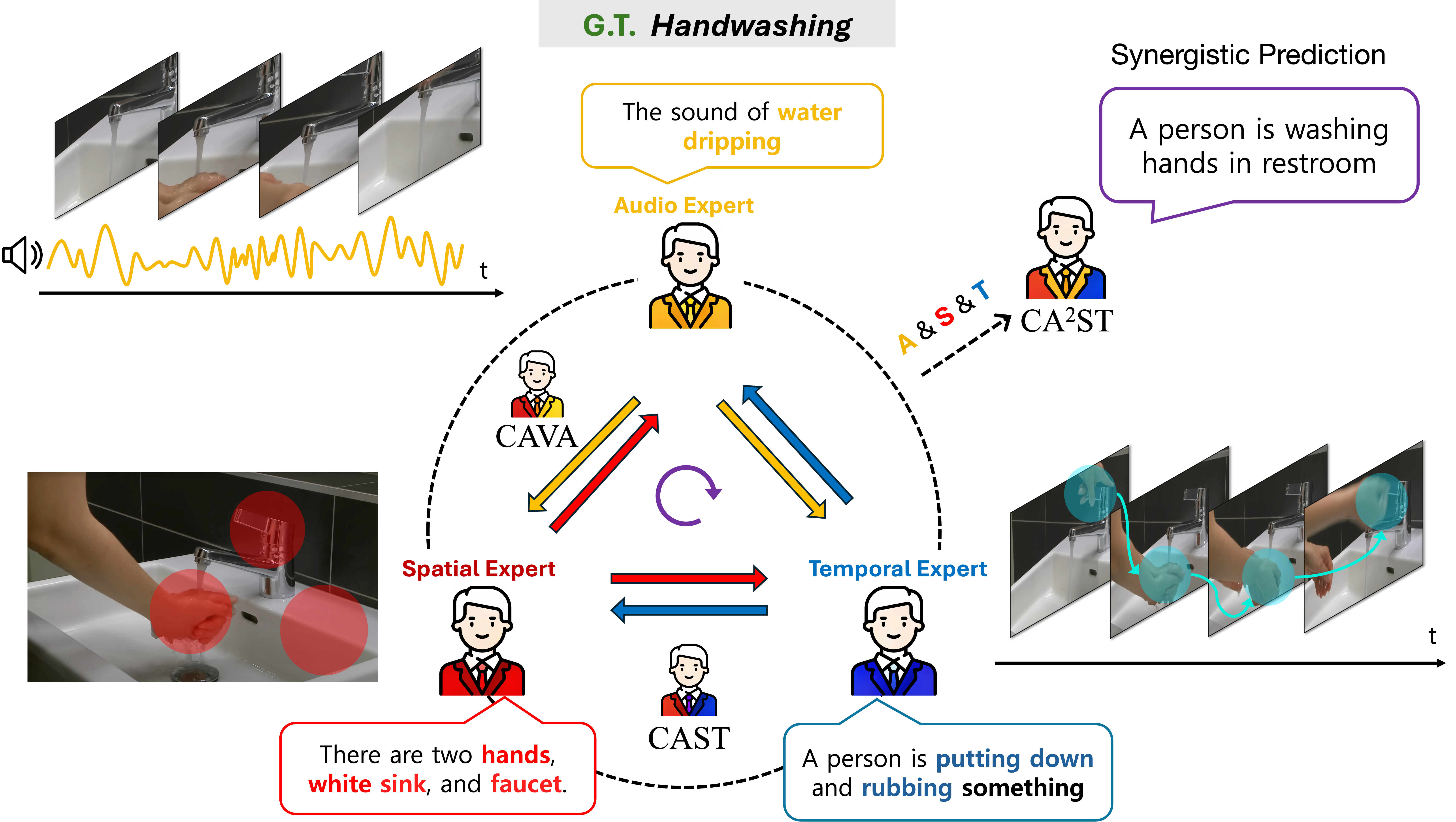
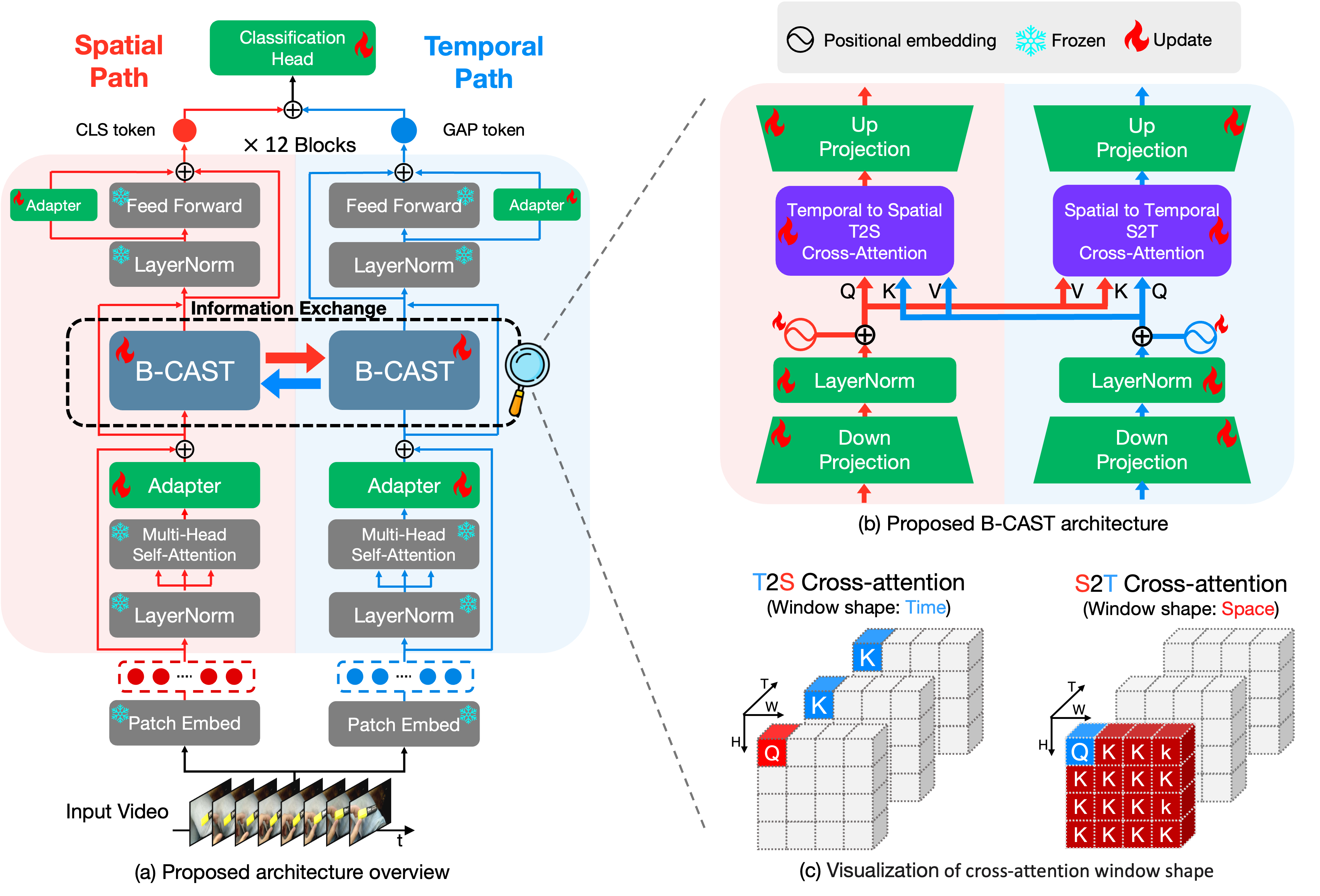
🧑💻 About Me

Jongseo Lee
🎓 M.S. Student in Computer Science
🏛 Kyung Hee University
🔬 Vision and Learning Lab, Advised by Prof. Jinwoo Choi
📧 jong980812@khu.ac.kr
🎓 Education
- 📌 B.S. in Biomedical Engineering, Kyung Hee University (2017 – 2023.2)
- 📌 B.S. in Electronics Engineering, Kyung Hee University (2020 – 2023.7)
- 📌 M.S. in Computer Science, Kyung Hee University (2023.8 – 2025.08)
- 📌 Post Master in Computer Science, Kyung Hee University (2025.09~)
Hello! I am currently pursuing a Master’s degree in Computer Science at Kyung Hee University, with one semester remaining until graduation.
Prior to my graduate studies, I earned dual bachelor's degrees in Biomedical Engineering and Electronics Engineering. This interdisciplinary background has given me a strong foundation in signal processing, embedded systems, and AI, which I now integrate into my research.
My research is conducted at the Vision and Learning Lab under Professor Jinwoo Choi, where I specialize in Video Understanding. I am particularly focused on:
- 🎥 Video Action Recognition – Developing AI models that can accurately interpret human actions in videos.
- 📝 Video-Text Multimodal Learning – Integrating textual and visual information for richer video understanding.
- 🔍 Explainable AI (XAI) for Video Analysis – Making AI decisions more interpretable and trustworthy.
Recent, I am deeply passionate about Video-eXplainable-AI and Video-Text multimodal learning . I am always open to collaboration and discussions on cutting-edge research in Computer Vision, Multimodal AI, and Explainability.
Feel free to connect with me! 🚀