Abstract
💡 Motivation
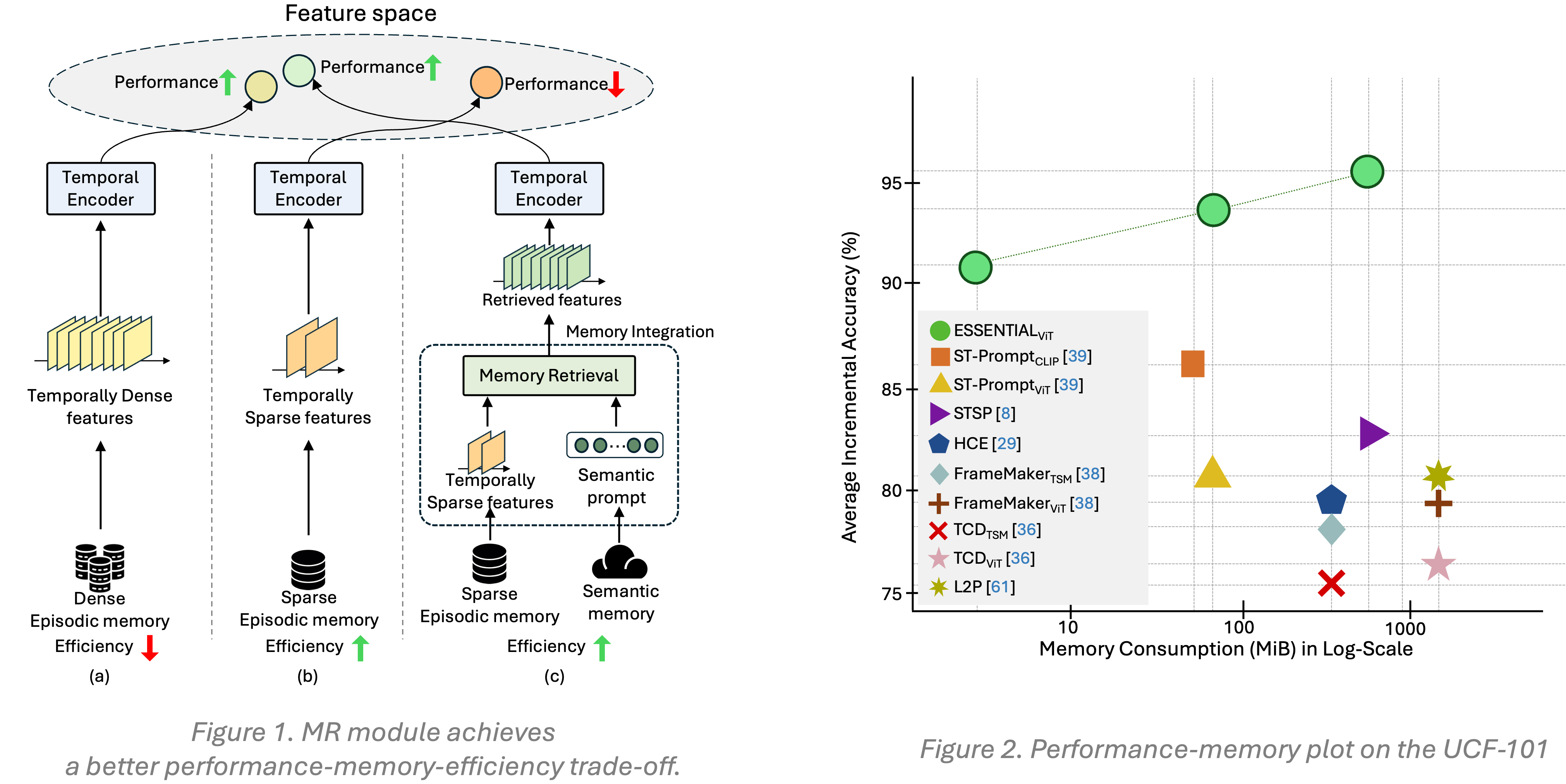
ESSENTIAL is designed to overcome the trade-off in VCIL between performance and memory-efficiency.
In Figure1,
- 📉 (a) Temporally dense features stored in episodic memory yield high performance but suffer from low memory-efficiency.
- 💾 (b) Temporally sparse features improve memory-efficiency, but lack of temporal context leads to performance degradation.
- ⚖️ (c) ESSENTIAL combines the best of both: storing temporally sparse features and lightweight semantic prompts to maintain efficiency, while the MR module integrates episodic and semantic memory to reconstruct temporally dense features.
The distance between the retrieved feature vector and the original temporally dense feature vector is significantly smaller than that between the temporally sparse feature vector and the temporally dense feature vector.
By effectively retrieving temporal information from temporally sparse features, the MR module enables a high memory-efficiency-performance trade-off as demonstrated in Figure 2.
🎯 Philosophy
The core philosophy of ESSENTIAL is to achieve a better trade-off between memory-efficiency and performance in video class-incremental learning.
-
Reducing memory consumption
We store only temporally sparse features in episodic memory, instead of temporally dense features, along with lightweight semantic prompts. -
Mitigating catastrophic forgetting
To maintain high performance, the MR module retrieves temporally dense features during the rehearsal stage by applying cross-attention between temporally sparse features and semantic prompts. -
Training for effective retrieval
The MR module is trained at each incremental stage to reconstruct temporally dense features using the stored temporally sparse features and semantic prompts as input.
⚙️ Architecture

Visual and temporal feature extraction
ESSENTIAL uses a frozen visual encoder to obtain frame-level temporally dense features from the input video. These features are passed into a learnable temporal encoder, producing a clip-level representation that captures the video’s temporal dynamics.

Memory Retrieval (MR) module
The MR module is designed to reconstruct temporally dense features from stored temporally sparse features. It is trained with both static and temporal matching losses to ensure accurate retrieval. At its core, the MR module performs cross-attention between learnable semantic prompts and sparse features. Through training, the semantic prompts learn general knowledge, while the MR module learns to recover dense features using only sparse features and the prompts.

Rehearsal training with retrieved features
During rehearsal, the MR module integrates episodic memory and semantic memory via cross-attention, retrieving temporally dense features from temporally sparse features. These retrieved features are replayed for rehearsal training, allowing ESSENTIAL to mitigate catastrophic forgetting while maintaining high memory-efficiency.
📈 Experimental Results
📊 Comparison with the state-of-the-arts on the vCLIMB Benchmark
We report the Top-1 average accuracy (%) and the total memory usage (MiB). We indicate the backbone model in parentheses. The best are in bold, and the second best are underscored. A dash (-) denotes a value not reported in the original paper. ESSENTIAL achieves the best performance with minimal memory consumption across all datasets in the benchmark.

📊 Comparison with the state-of-the-arts on the TCD Benchmark
We report the Top-1 average incremental accuracy (%) and the total memory usage (MiB). We indicate the backbone model in parentheses. An asterisk (*) denotes estimated memory usage. The best are in bold and the second best are underscored.

🔍 Ablation study
We conduct extensive ablation studies to examine the design choices of the proposed method on the SSV2 (10 × 9 tasks).

Analysis

Is ESSENTIAL robust to a decreasing number of frame features?
The results indicate that ESSENTIAL effectively mitigates forgetting even when storing temporally sparse features, thanks to the retrieval capability of the MR module. This retrieval enables us to store only temporally sparse features in episodic memory, leading to high memory-efficiency.

Does the MR module effectively retrieve temporally dense features?
We can qualitatively observe that the retrieved feature vectors, \(( \tilde{\mathbf{S}}_{\text{dense}}, \textcolor[rgb]{0.0,0.6,0.0}{\text{circles}} )\), are closer to the original temporally dense feature vectors, \(( \mathbf{S}_{\text{dense}}, \textcolor[rgb]{0.0,0.35,0.7}{\text{crosses}} )\), compared to the sparse feature vectors, \(( \mathbf{S}_{\text{sparse}}, \textcolor[rgb]{0.8,0.2,0.2}{\text{squares}} )\). This result indicates that the MR module effectively retrieves temporally dense features from temporally sparse features.
Citation
@inproceedings{lee2025essential,
title={ESSENTIAL: Episodic and Semantic Memory Integration for Video Class-Incremental Learning},
author={Lee, Jongseo and Bae, Kyungho and Min, Kyle and Park, Gyeong-Moon and Choi, Jinwoo},
booktitle={ICCV},
year={2025}
}